How OpenVINO GenAI Works
Stateful LLM
A common optimization for LLM inference is using a past KV (key/value)-cache. This cache is represented by the corresponding inputs and outputs in a model originally implemented in a DL framework (e.g. PyTorch models from Hugging Face). For further optimization and easier use, the model is transformed to a stateful form. This transformation improves inference performance and decreases the allocated runtime memory in long-running text generation scenarios. It is achieved by hiding inputs and outputs of the model that represent past KV-cache tensors and handling them inside the model in a more efficient way. Although the cache is still accessible with state API. It is opposed to stateless model approach requiring manipulating these inputs and outputs explicitly. An introduction to the stateful models can be found in the Stateful Models article.
Beam Search and KV-Cache
Hiding KV-cache introduces a peculiarity for beam search algorithm. Beam search suggests batched inference of multiple beams. The design described here so far would result in generating multiple independent sequences of tokens. Beam search algorithm, on the other hand, requires removing some of the ongoing beams and splitting other beams to multiple branches. Beam removal requires deleting corresponding KV-cache entry and beam splitting requires copying corresponding KV-cache values.
To provide the possibility to implement beam search without accessing model's internal state, a stateful LLM converted with optimum-intel or llm_bench introduces an additional 1-dimentional beam_idx input. beam_idx must contain indexes of elements in a batch which are intended to be selected and will evolve during the next beam search iteration. There's only one beam when the generation starts. That beam corresponds to the initial prompt. beam_idx must have values: [0, 0] to keep the initial beam and introduce its copy. The dynamic batch size enables to change the number of beams dynamically. beam_idx must have [1] as the value to remove zeroth sequence and keep the second beam only.
Assume there are two running beams. To proceed with generating both beams at the next iteration, beam_idx values must be [0, 1], pointing to batch elements 0 and 1. To drop the last beam and split the other beam in two, beam_idx must be set to [0, 0]. This results in utilizing only the part of KV cache corresponding to the zeroth element in the batch. The process of selecting proper entries in cache is called Cache Reorder.
Forking Beam Example
In this diagram, setting beam_idx = [0, 0] creates two identical copies of Beam 0, which can then diverge in future iterations:
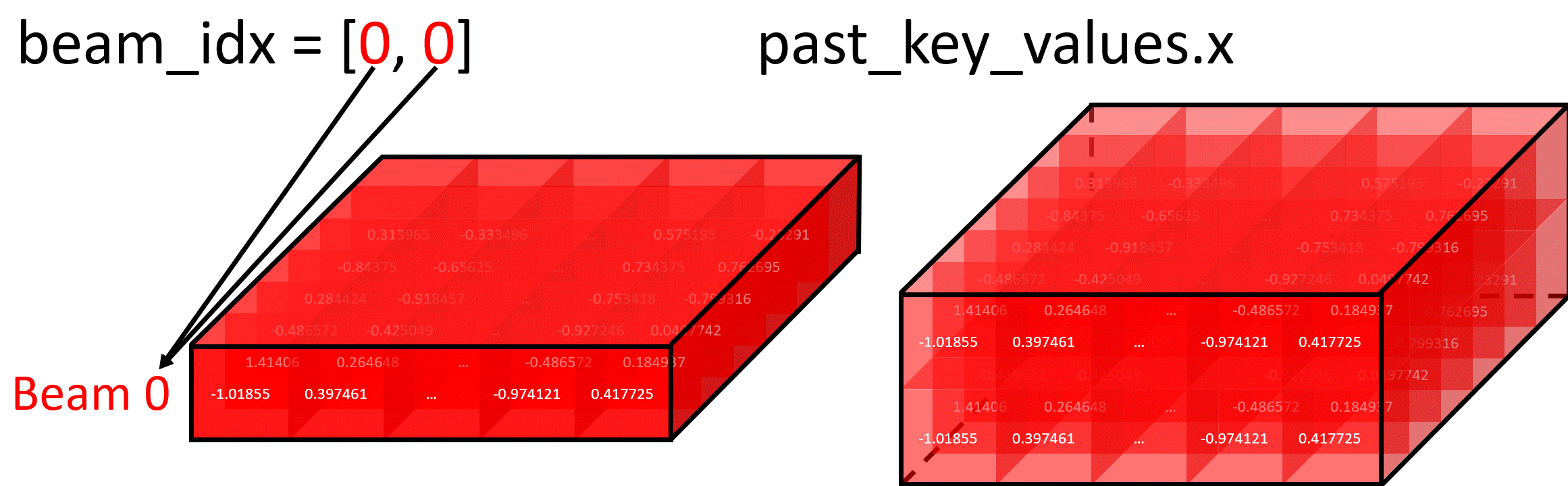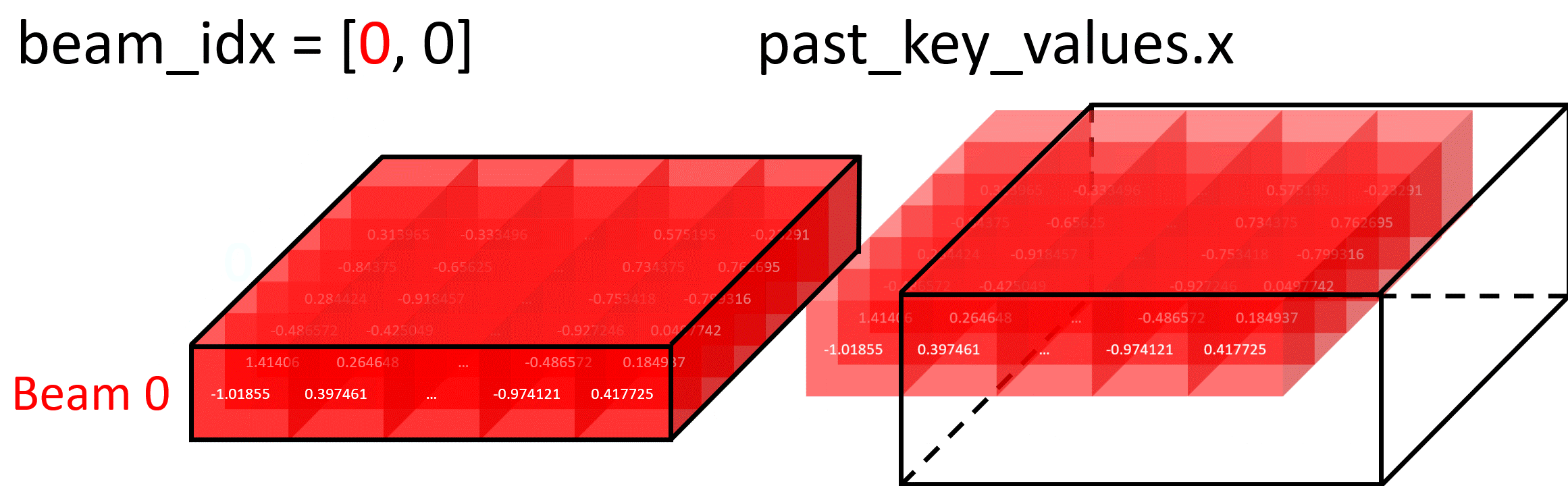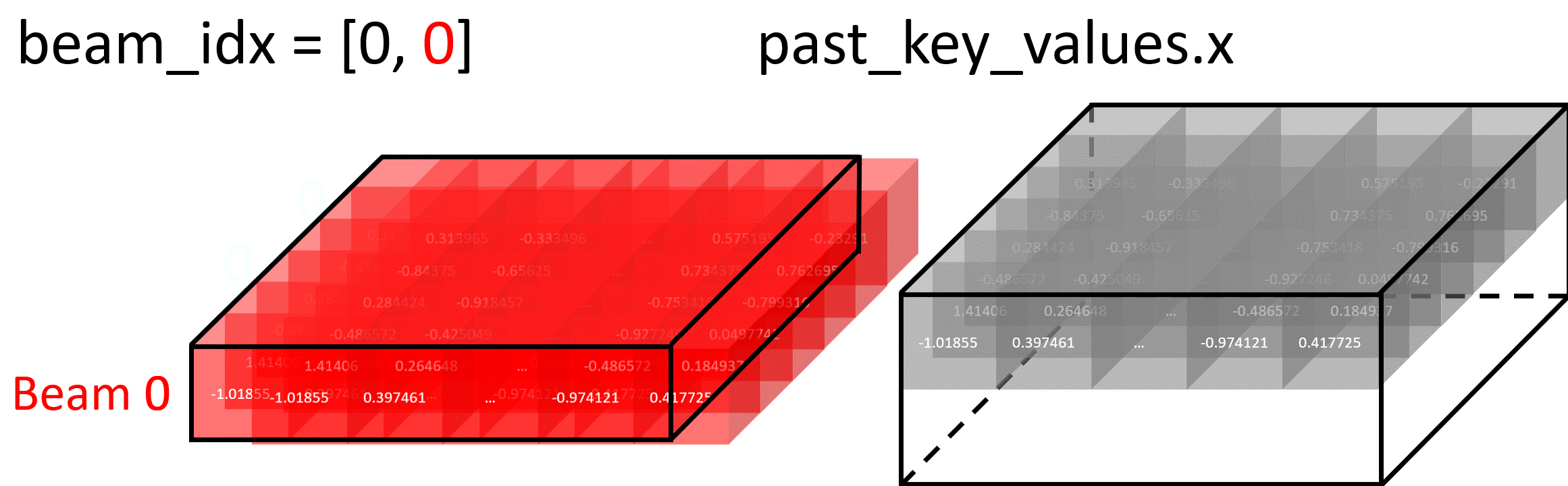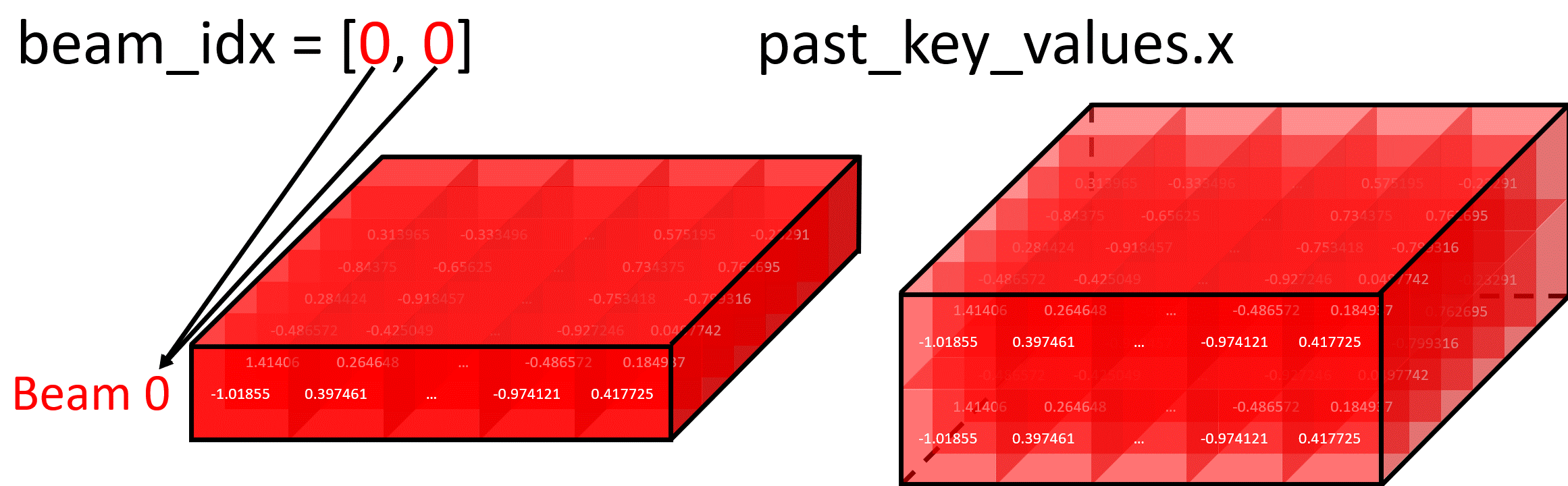
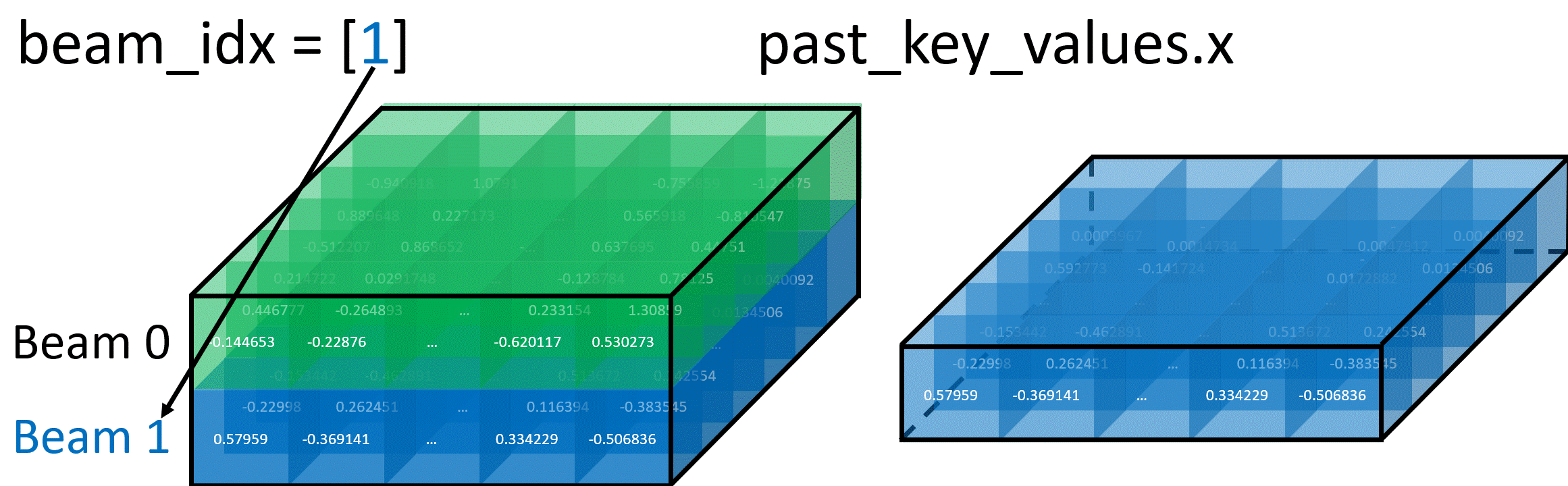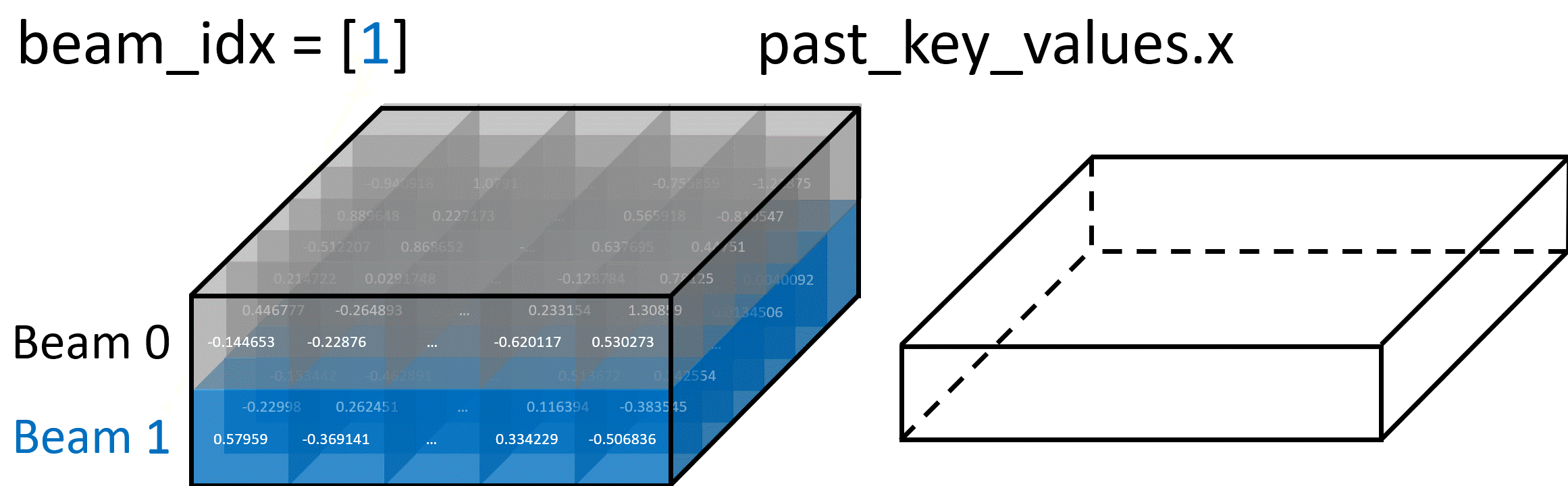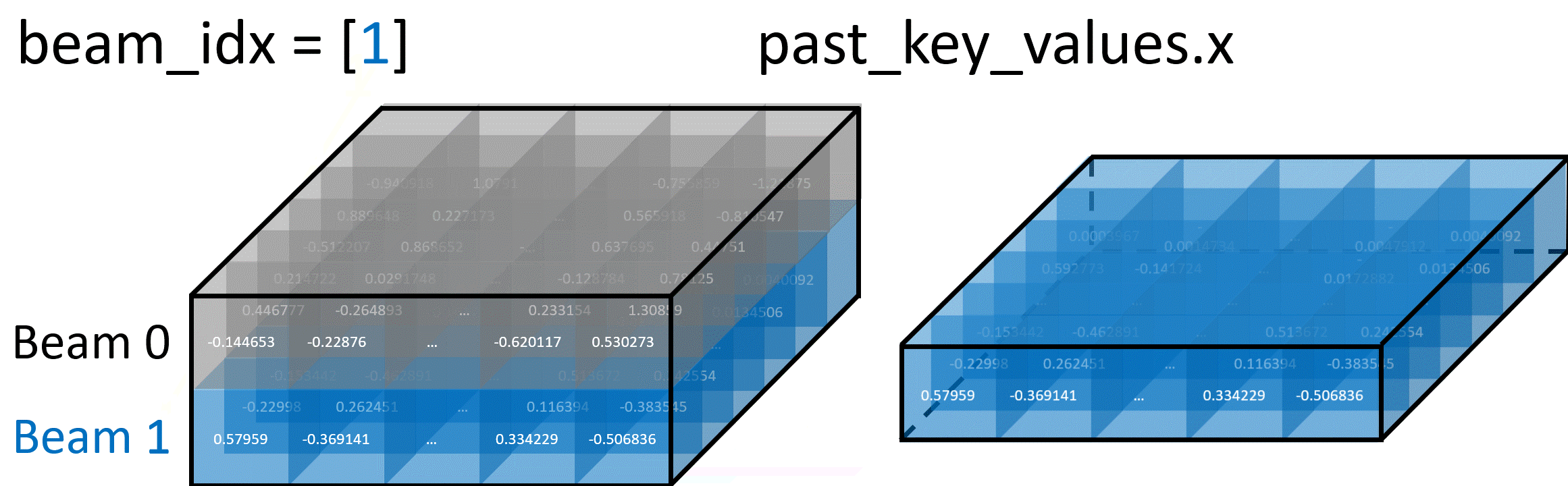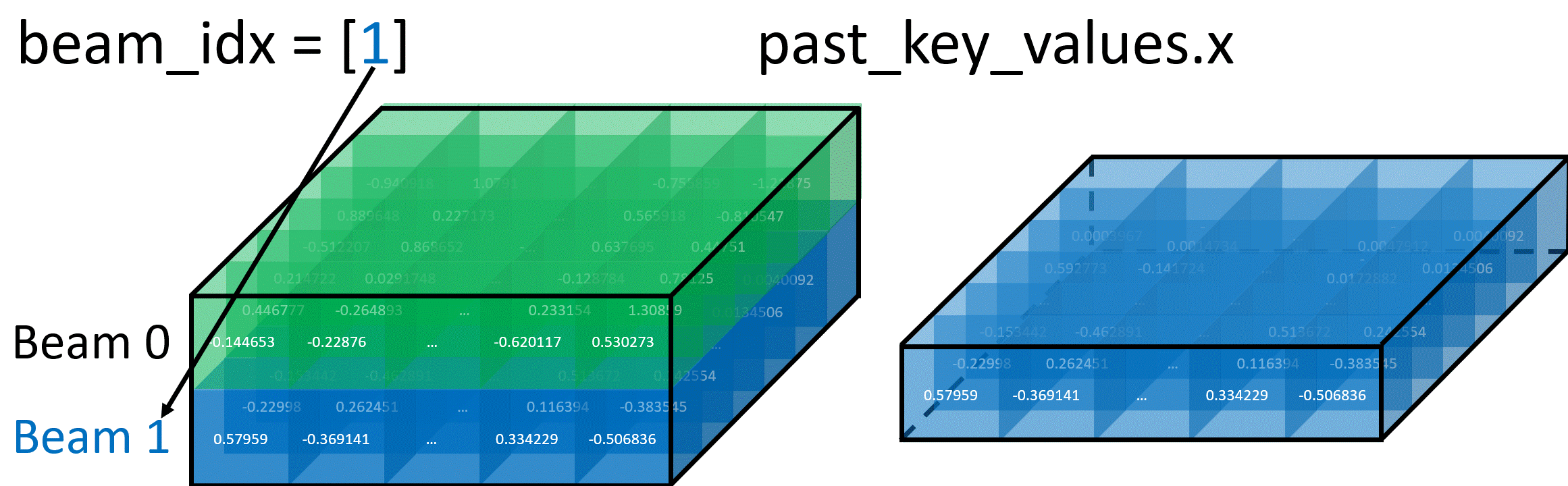
Selecting Specific Beam Example
The diagram below shows how setting beam_idx = [1] selects only Beam 1 from the KV-cache, effectively removing Beam 0 from consideration in the next iteration:
Stateless vs Stateful Models
The images below represent stateless and stateful LLM pipelines. The model has the following inputs:
input_idscontains the next selected tokenattention_maskis filled with1position_idsencodes a position of currently generating token in the sequencebeam_idxselects beams
The model has 1 output logits describing the predicted distribution over the next tokens. And there's KV cache state.
Stateless Pipeline
In the stateless model approach, the developer needs to manage all KV-cache inputs and outputs explicitly:
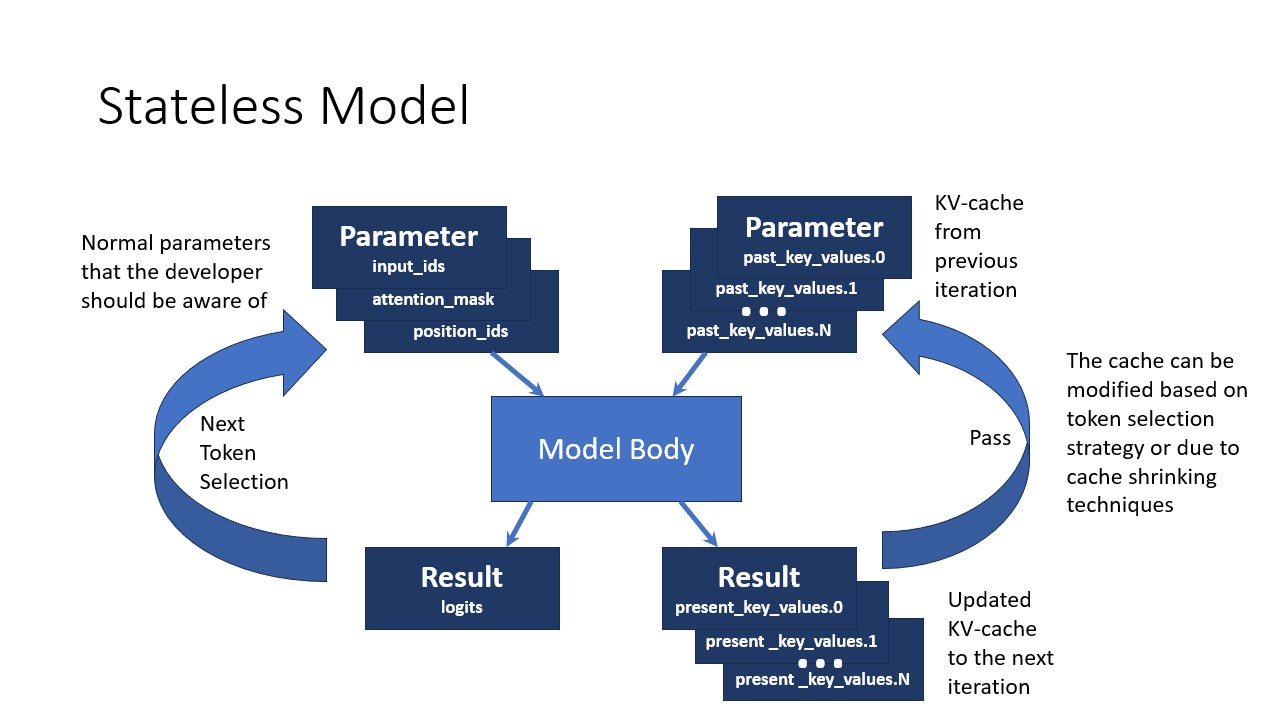
With a stateless model:
- Normal parameters (
input_ids,attention_mask,position_ids) must be managed by the developer - KV-cache from previous iterations (
past_key_values) must be passed as inputs - Updated KV-cache (
present_key_values) must be handled as outputs - The cache can be modified based on token selection strategy or due to cache shrinking techniques
Stateful Pipeline
In the stateful model with Cache Reorder, much of the KV-cache management is handled internally:
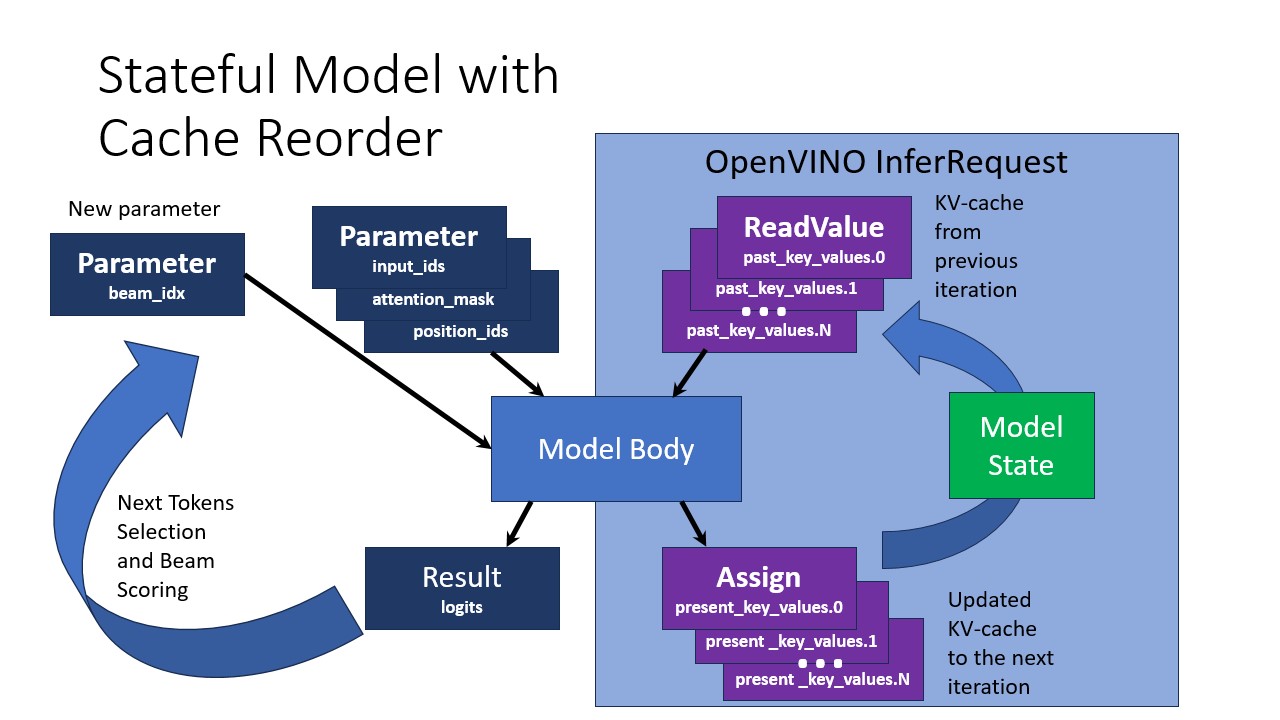
With a stateful model:
- A new
beam_idxparameter is introduced to manage beam selection - KV-cache is stored in the Model State within the OpenVINO InferRequest
- ReadValue operations retrieve the KV-cache from previous iterations
- Assign operations update the KV-cache for the next iteration
- Next token selection and beam scoring are simplified