Low-Rank Adaptation (LoRA)
LoRA, or Low-Rank Adaptation, is a popular and lightweight training technique used for fine-tuning Large Language and Stable Diffusion Models without needing full model training. Full fine-tuning of larger models (consisting of billions of parameters) is inherently expensive and time-consuming. LoRA works by adding a smaller number of new weights to the model for training, rather than retraining the entire parameter space of the model. This makes training with LoRA much faster, memory-efficient, and produces smaller model weights (a few hundred MBs), which are easier to store and share.
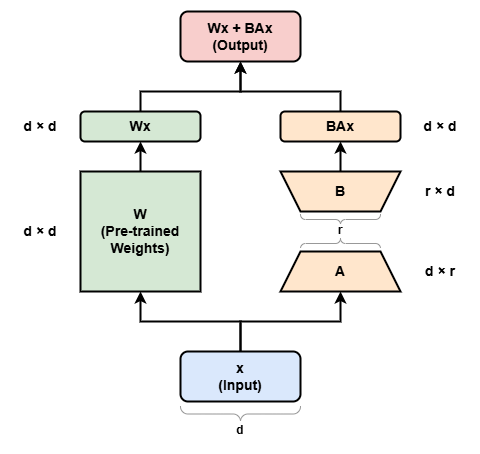
At its core, LoRA leverages the concept of low-rank matrix factorization. Instead of updating all the parameters in a neural network, LoRA decomposes the parameter space into two low-rank matrices. This decomposition allows the model to capture essential information with fewer parameters, significantly reducing the amount of data and computation required for fine-tuning. This vastly reduces the storage requirement for large language models adapted to specific tasks and enables efficient task-switching during deployment all without introducing inference latency.
Some more advantages of using LoRA:
- LoRA makes fine-tuning more efficient by drastically reducing the number of trainable parameters.
- The original pre-trained weights are kept frozen, which means you can have multiple lightweight and portable LoRA models for various downstream tasks built on top of them.
- LoRA is orthogonal to many other parameter-efficient methods and can be combined with many of them.
- Performance of models fine-tuned using LoRA is comparable to the performance of fully fine-tuned models.
- LoRA does not add any inference latency because adapter weights can be merged with the base model.
More details about LoRA can be found in HuggingFace conceptual guide and blog post.
See LoRA Adapters Guide for an example of using LoRA with OpenVINO GenAI.