Auto-configuration#
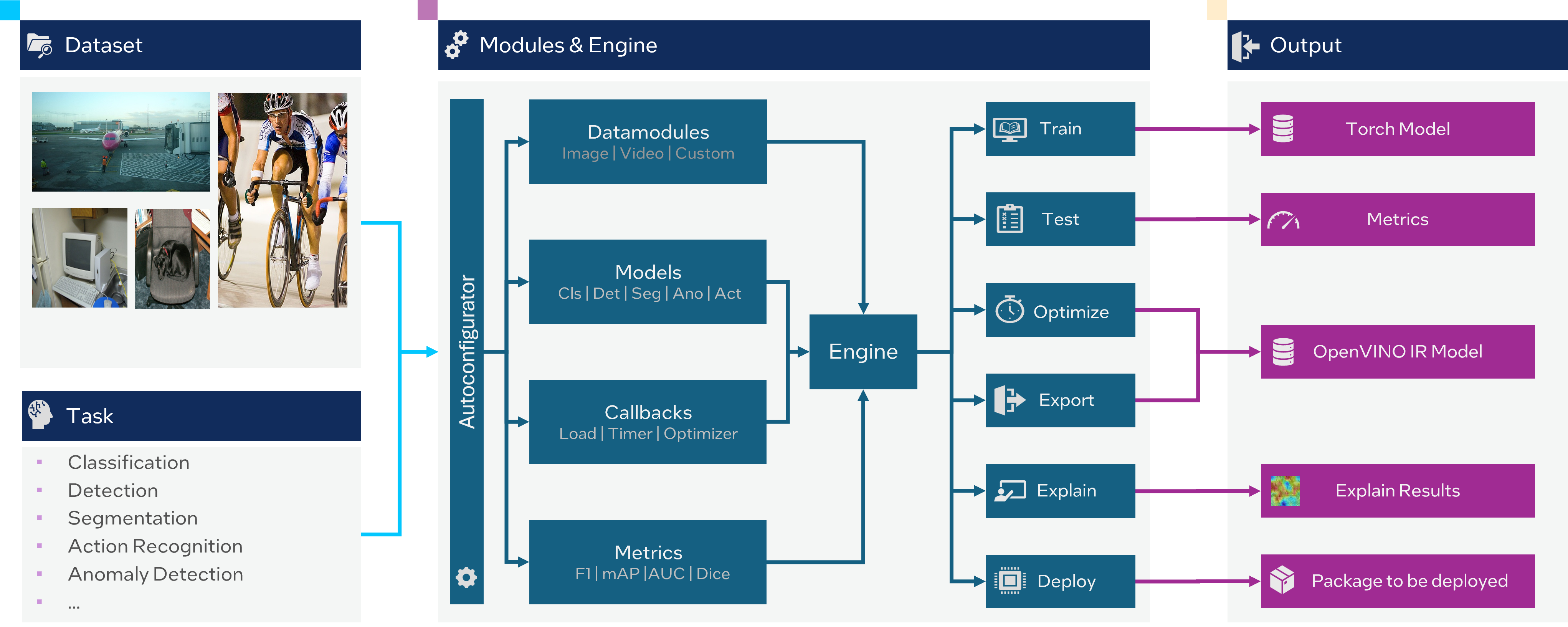
Auto-configuration for a deep learning framework means the automatic finding of the most appropriate settings for the training parameters, based on the dataset and the specific task at hand. Auto-configuration can help to save time, it eases the process of interaction with OpenVINO™ Training Extensions and gives a better baseline for the given dataset.
At this end, we developed a simple auto-configuration functionality to ease the process of training and validation utilizing our framework. Basically, to start the training and obtain a good baseline with the best trade-off between accuracy and speed we need to pass only a dataset in the right format without specifying anything else:
from otx.engine import Engine
engine = Engine(data_root="<path_to_data_root>")
engine.train()
(otx) ...$ otx train ... --data_root <path_to_data_root>
After dataset preparation, the training will be started with the middle-sized recipe to achieve competitive accuracy preserving fast inference.
Supported dataset formats for each task:
classification: Imagenet, COCO (multi-label), custom hierarchical
object detection: COCO, Pascal-VOC, YOLO
semantic segmentation: Common Semantic Segmentation, Pascal-VOC, Cityscapes, ADE20k
anomaly: MVTec
instance segmentation: COCO, Pascal-VOC
keypoint detection: COCO
If we have a dataset format occluded with other tasks, for example COCO format, we should directly emphasize the task type. If not, OpenVINO™ Training Extensions automatically chooses the task type that you might not intend:
from otx.engine import Engine
engine = Engine(data_root="<path_to_data_root>", task="<TASK_TYPE>")
engine.train()
(otx) ...$ otx train --data_root <path_to_data_root>
--task {MULTI_CLASS_CLS, MULTI_LABEL_CLS, H_LABEL_CLS, DETECTION, INSTANCE_SEGMENTATION, SEMANTIC_SEGMENTATION, ANOMALY, KEYPOINT_DETECTION}
...
Auto-adapt batch size#
This feature adapts a batch size based on the current hardware environment. There are two methods available for adapting the batch size.
Prevent GPU Out of Memory (Safe mode)
The first method checks if the current batch size is compatible with the available GPU devices. Larger batch sizes consume more GPU memory for training. Therefore, the system verifies if training is possible with the current batch size. If it’s not feasible, the batch size is decreased to reduce GPU memory usage. However, setting the batch size too low can slow down training. To address this, the batch size is reduced to the maximum amount that could be run safely on the current GPU resource. The learning rate is also adjusted based on the updated batch size accordingly.
To use this feature, add the following parameter:
from otx.engine import Engine
engine = Engine(data_root="<path_to_data_root>")
engine.train(adaptive_bs="Safe")
(otx) ...$ otx train ... --adaptive_bs Safe
Find the maximum executable batch size (Full mode)
The second method aims to find a possible large batch size that reduces the overall training time. Increasing the batch size reduces the effective number of iterations required to sweep the whole dataset, thus speeds up the end-to-end training. However, it does not search for the maximum batch size as it is not efficient and may require significantly more time without providing substantial acceleration compared to a large batch size. Similar to the previous method, the learning rate is adjusted according to the updated batch size accordingly.
To use this feature, add the following parameter:
from otx.engine import Engine
engine = Engine(data_root="<path_to_data_root>")
engine.train(adaptive_bs="Full")
(otx) ...$ otx train ... --adaptive_bs Full
Warning
When using a fixed epoch, training with larger batch sizes is generally faster than with smaller batch sizes. However, if early stop is enabled, training with a lower batch size can finish early.
Auto-adapt num_workers#
This feature adapts the num_workers parameter based on the current hardware environment.
The num_workers parameter controls the number of subprocesses used for data loading during training.
While increasing num_workers can reduce data loading time, setting it too high can consume a significant amount of CPU memory.
To simplify the process of setting num_workers manually, this feature automatically determines the optimal value based on the current hardware status.
To use this feature, add the following parameter:
from otx.core.data.module import OTXDataModule
datamodule = OTXDataModule(..., auto_num_workers=True)
(otx) ...$ otx train ... --data.auto_num_workers True