Arrow#
Format specification#
Apache Arrow is a in-memory columnar table format specification with multiple language support. This format supports to export into a single arrow file or multiple shardings.
Table schema#
id |
subset |
media.type |
media.path |
media.bytes |
media.attributes |
annotations |
attributes |
|---|---|---|---|---|---|---|---|
string |
string |
uint32 |
string |
binary |
binary |
binary |
binary |
id (string)#
The ID of each entity. A tuple of (id, subset) is a unique key of each entity.
subset (string)#
The subset the entity belongs to. A tuple of (id, subset) is a unique key of each entity.
media.type (uint32)#
The type of media the entity has.
Supported media types:
0:
None2:
Image6:
PointCloud
media.path (string)#
The path of the media. It could be a real path or a relative path, or /NOT/A/REAL/PATH if path is invalid.
media.bytes (binary)#
The binary data of the media. It could be None if one chooses not to save media when export.
media.attributes (binary)#
The attribute of the entity. The contents of it depends on media.type.
The byte order is little-endian.
Image

PointCloud

annotations (binary)#
The annotations of the entity. The byte order is little-endian. The annotations are more than one like following.

Supported annotation types:
1:
Label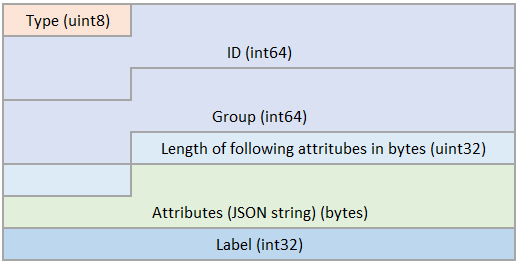
2:
Mask
3:
Points
4:
Polygon
5:
PolyLine6:
Bbox7:
Caption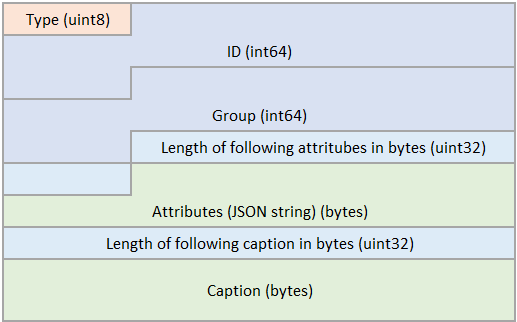
8:
Cuboid3d
11:
Ellipse
attributes (binary)#
The attributes of the entity. The byte order is little-endian.

Import Arrow dataset#
A Datumaro project with a Arrow source can be created in the following way:
datum project create
datum project import --format arrow <path/to/dataset>
It is possible to specify project name and project directory. Run
datum project create --help for more information.
An Arrow dataset directory should have the following structure:
└─ Dataset/
├── <subset_name_1>-0-of-2.arrow
├── <subset_name_1>-1-of-2.arrow
├── <subset_name_2>-0-of-1.arrow
└── ...
If your dataset is not following the above directory structure, it cannot detect and import your dataset as the Arrow format properly.
To make sure that the selected dataset has been added to the project, you can
run datum project pinfo, which will display the project information.
Export to other formats#
It can convert Datumaro dataset into any other format Datumaro supports. To get the expected result, convert the dataset to formats that support the specified task (e.g. for panoptic segmentation - VOC, CamVID)
There are several ways to convert a Datumaro dataset to other dataset formats using CLI:
Export a dataset from Datumaro format to VOC format:
datum project create
datum project import -f arrow <path/to/dataset>
datum project export -f voc -o <output/dir>
or
datum convert -if arrow -i <path/to/dataset> -f voc -o <output/dir>
Or, using Python API:
import datumaro as dm
dataset = dm.Dataset.import_from('<path/to/dataset>', 'arrow')
dataset.export('save_dir', 'voc', save_media=True, image_ext="AS-IS", num_workers=4)
Export to Arrow#
There are several ways to convert a dataset to Arrow format:
Export a dataset from an existing project to Arrow format:
# export dataset into Arrow format from existing project
datum project export -p <path/to/project> -f arrow -o <output/dir> \
-- --save-media
Convert a dataset from VOC format to Arrow format:
# converting to arrow format from other format
datum convert -if voc -i <path/to/dataset> \
-f arrow -o <output/dir> -- --save-media
Extra options for exporting to Arrow format:
--save-mediaallow to export dataset with saving media files. (default:False)--image-ext IMAGE_EXTallow to choose which scheme to use for image when--save-mediaisTrue. (default:AS-IS)Available options are (
AS-IS,PNG,TIFF,JPEG/95,JPEG/75,NONE)--max-shard-size MAX_SHARD_SIZEallow to specify maximum number of dataset items when saving into arrow format. (default:1000)--num-shards NUM_SHARDSallow to specify the number of shards to generate.--num-shardsand--max-shard-sizeare mutually exclusive. (default:None)--num-workers NUM_WORKERSallow to multi-processing for the export. If num_workers = 0, do not use multiprocessing (default:0).
Examples#
Examples of using this format from the code can be found in the format tests